World models are learned approximations of how an environment changes. Imagine a robot arm trying to pick up a mug. If it moves the gripper slightly left, will it make contact? If it closes too early, will the mug slip? A world model is the part that tries to predict these consequences before the robot commits to an action.
This is useful, because an agent can evaluate possible actions without testing all of them in the real environment. That matters when real interaction is expensive, slow, or risky. The limitation is that planning is only as good as the model. If the learned simulator is wrong, the agent can choose actions that look good inside the model but fail in the real environment.
Starting example: a tiny learned gridworld
Take a small slippery gridworld. The agent starts at S, wants to reach G, and has to learn what its actions actually do. The black cells are walls (see gif below).
The floor is slippery. If the agent tries to move up, it usually moves up, but sometimes slips sideways. That small bit of randomness matters. The model is no longer learning a hard-coded rule like “up changes the row by one”; it is learning a distribution over outcomes.
Here the state is just the square the agent is standing on. For each square and intended action, the model estimates:
\[\hat{p}(z_{t+1} \mid z_t, a_t)\]Here $z_t$ is the current square, $a_t$ is the action the agent tries to take, and $z_{t+1}$ is the square it actually lands on. The hat on $\hat{p}$ is a reminder that this is the model’s estimate, not a rule we gave it by hand.
After each round of experience, I ask: under the model we have learned so far, which move looks best from each square? At the beginning, the answer is mostly noise. As the transition estimates improve, the planned path becomes reasonable.
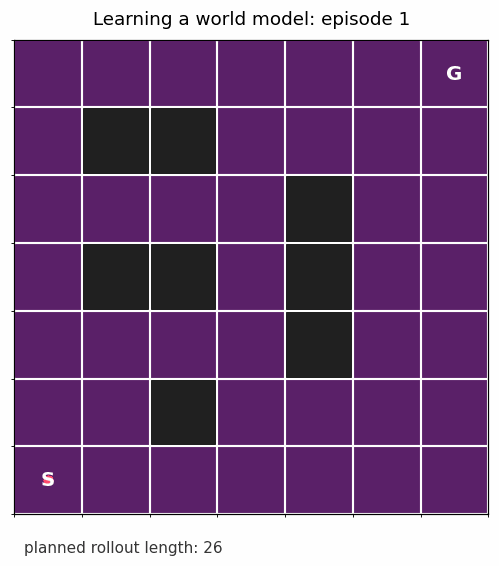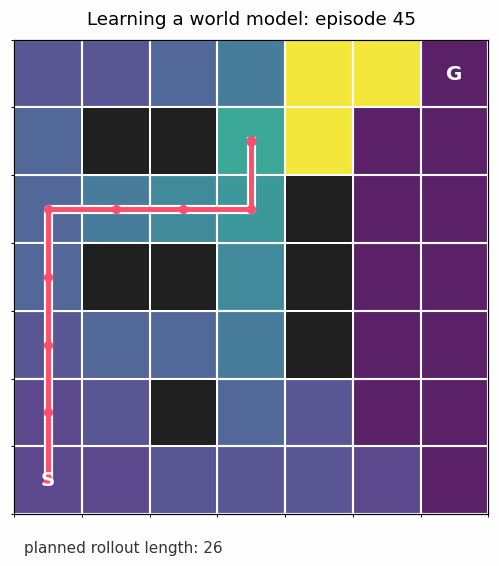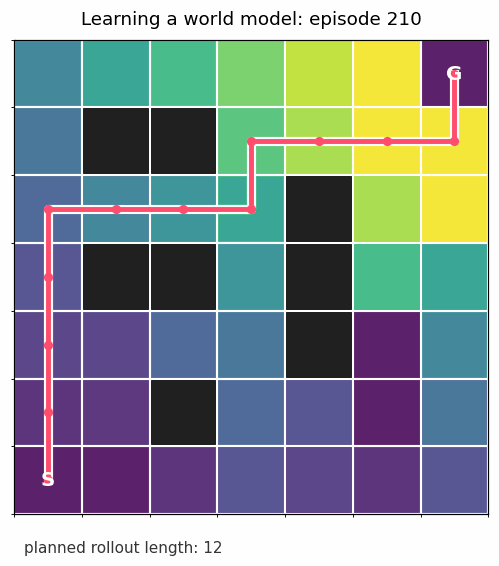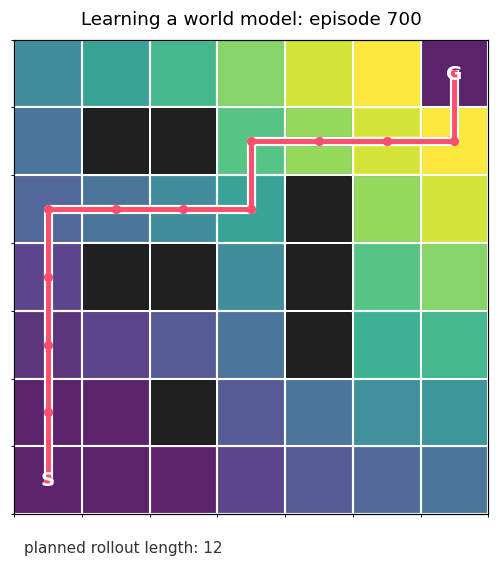
Once the transition model is good enough, we can roll it forward from the start state without touching the real environment:
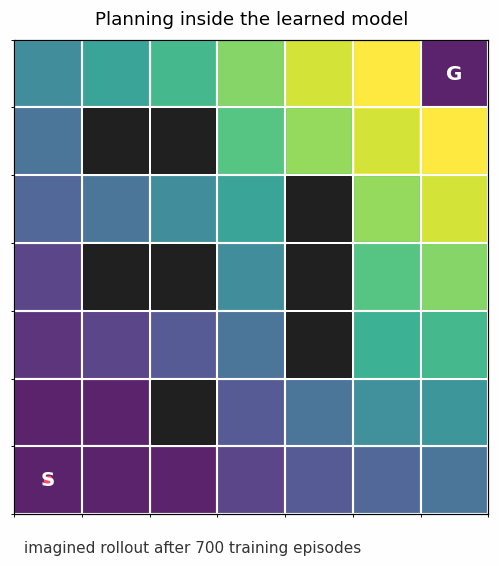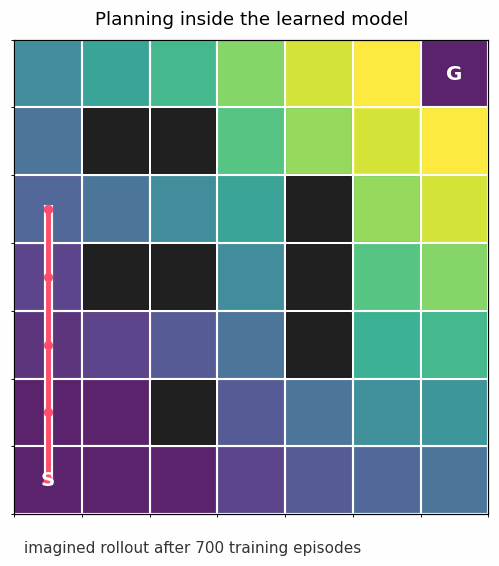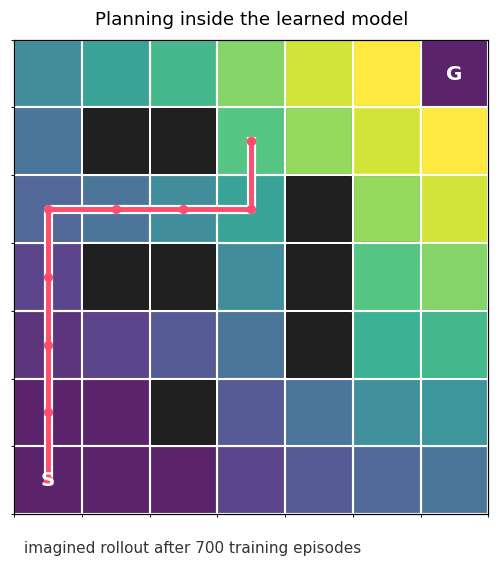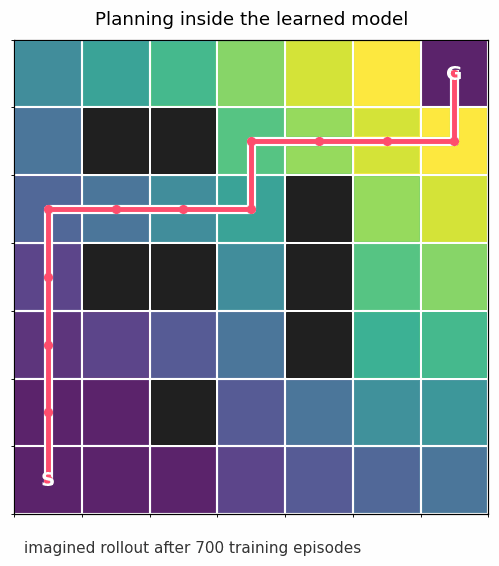
That is the whole pattern in miniature: learn dynamics, plan with the learned dynamics, collect more data, repeat.
Model-based learning
The gridworld example was deliberately tiny. In reinforcement learning notation, the same loop looks like this: an agent observes $o_t$, takes an action $a_t$, receives a reward $r_t$, and moves to the next observation $o_{t+1}$.
A model-free agent tries to learn good actions directly. A model-based agent also tries to learn how the environment changes:
\[p(o_{t+1}, r_t \mid o_t, a_t)\]With a perfect model, planning is conceptually easy: try candidate action sequences, estimate their consequences, and choose the best one. Real observations make this messy. Images contain shadows, textures, backgrounds, and other details that may be irrelevant for the decision.
So we usually do not model raw observations directly. We first compress them.
Latent states
A latent state is the compressed version of the observation:
\[z_t = e_\phi(o_t)\]The latent state should keep what matters for prediction and control. For a driving agent, that might include lane geometry, nearby cars, traffic lights, and velocity. It probably does not need the exact texture of the pavement.
The dynamics model then predicts the next latent state:
\[z_{t+1} \sim p_\theta(z_{t+1} \mid z_t, a_t)\]The model now has a more manageable job: predict how this compact state changes when the agent acts.
Components of a world model
A typical implementation has a few learned pieces:
- Encoder: maps observations to latent states.
- Dynamics model: predicts the next latent state.
- Decoder: reconstructs observations from latent states.
- Reward model: predicts rewards from latent states and actions.
In equations:
\[z_t = e_\phi(o_t)\] \[z_{t+1} \sim p_\theta(z_{t+1} \mid z_t, a_t)\] \[\hat{o}_t \sim d_\psi(o_t \mid z_t)\] \[\hat{r}_t = r_\eta(z_t, a_t)\]The decoder is useful when we want the latent state to preserve enough information to reconstruct the observation. But reconstruction is not always the goal. If the model is only used for control, rewards, values, and future states may matter more. This distinction comes back when we get to MuZero.
Training the model
The training data is a set of trajectories collected from the environment:
\[(o_1, a_1, r_1, o_2), (o_2, a_2, r_2, o_3), \ldots, (o_T, a_T, r_T, o_{T+1})\]In the gridworld, training is just counting. If the agent is in square $z_t$, tries action $a_t$, and lands in square $z_{t+1}$, we increment that transition count. Because the floor is slippery, the same intended action can lead to different next squares on different attempts. The learned transition probability is:
\[\hat{p}(z' \mid z, a) = \frac{N(z, a, z')}{\sum_{\tilde{z}} N(z, a, \tilde{z})}\]where $N(z, a, z’)$ is the number of times intended action $a$ took the agent from $z$ to $z’$. The reward model is just the average observed reward for each state-action pair:
\[\hat{r}(z, a) = \frac{1}{N(z, a)} \sum_{i: z_i=z, a_i=a} r_i\]The gridworld gets to use tables because the state is handed to us. Neural world models have to learn the state representation and the dynamics at the same time.
One simple deterministic setup is:
- Encode the current observation into a latent state:
- Predict the next latent state after taking action $a_t$:
- Decode the latent state back into an observation:
- Predict the reward:
The loss asks for three things:
- the decoded observation should look like the real observation;
- the predicted next latent state should match the encoding of the next real observation;
- the predicted reward should match the reward the environment returned.
Written compactly:
\[\mathcal{L} = \sum_t \lambda_o \lVert o_t - \hat{o}_t \rVert^2 + \lambda_z \lVert e_\phi(o_{t+1}) - \hat{z}_{t+1} \rVert^2 + \lambda_r \lVert r_t - \hat{r}_t \rVert^2\]The middle term is the interesting one. The dataset does not contain a true latent state. We create the target by encoding the next observation, $e_\phi(o_{t+1})$, and train the dynamics model to predict that. This couples the encoder and dynamics model: the latent state should describe the observation, but it also has to be predictable after an action.
Many modern world models make this probabilistic. Instead of saying “the state is exactly $z_t$”, the encoder gives a distribution over possible states after seeing the observations:
\[q_\phi(z_t \mid o_{\leq t}, a_{<t})\]The dynamics model gives a prior before seeing the current observation:
\[p_\theta(z_t \mid z_{t-1}, a_{t-1})\]The prior has less information because it only sees the previous latent state and action. The KL term keeps these two views of the latent state close:
\[D_{KL}\left( q_\phi(z_t \mid o_{\leq t}, a_{<t}) \Vert p_\theta(z_t \mid z_{t-1}, a_{t-1}) \right)\]This discourages a representation that is easy to reconstruct from but impossible to roll forward. For planning, a representation that cannot be predicted is not very useful.
Planning and imagination
After training, the learned model becomes a small simulator. Starting from the current latent state, the agent can roll forward:
\[z_t \rightarrow z_{t+1} \rightarrow z_{t+2} \rightarrow \cdots\]At each imagined step, the agent picks an action, the dynamics model predicts the next latent state, and the reward model predicts the reward:
\[(z_t, a_t, \hat{r}_t, z_{t+1})\]There are two standard ways to use these imagined transitions:
- Planning: search over action sequences in the model and choose the best predicted one.
- Policy learning: train a policy on imagined rollouts, then execute it in the real environment.
The gridworld above uses planning. It learns transition probabilities, estimates which states are valuable, and follows the best action under that learned model.
Why this matters outside toy grids
In practice, a world model is usually a learned predictive model inside a system that needs to ask: if we do this, what probably happens next?
Self-driving is the easiest real example to picture. The car does not only need to detect lanes, cars, cyclists, and pedestrians in the current frame. It needs to forecast how the scene may evolve under possible actions. If the ego car slows down, will the pedestrian keep crossing? If it nudges left, will the neighboring car yield or close the gap? If it waits one more second, does the intersection become safer or more ambiguous?
That is a world-model-shaped problem:
\[\text{current traffic scene, ego action} \rightarrow \text{future traffic scene, risk}\]A useful model can be ugly as long as it keeps track of the things that would change the driving decision: where everyone is, how fast they are moving, who has right of way, and how unsure we should be. A rough prediction that says “this cyclist might enter my lane” is better than a beautiful prediction that is confidently wrong.
That is the appeal of world models: make the cheap mistakes in imagination before making an expensive one in the world. It is also the danger. If the imagined world is wrong, the agent can learn to exploit the mistake. The model has to know when it is uncertain, and the system has to keep checking its imagination against reality.
Dreamer
Dreamer is a strong example of the policy-learning route. It learns a latent dynamics model, generates imagined trajectories in that latent space, and trains an actor-critic agent on those trajectories.
The policy acts in latent space:
\[a_t \sim \pi_\omega(a_t \mid z_t)\]The value function estimates future return:
\[V_\xi(z_t) \approx \mathbb{E}\left[\sum_{k=t}^{T} \gamma^{k-t} r_k\right]\]The reconstructions can be imperfect. What matters is whether the imagined latent rollouts contain enough information to improve the policy.
MuZero
MuZero takes this even more directly. It drops observation reconstruction and learns only the pieces needed for planning: representation, dynamics, rewards, policies, and values.
It uses a representation function:
\[z_t = h_\phi(o_{\leq t})\]a dynamics function:
\[z_{t+1}, \hat{r}_t = g_\theta(z_t, a_t)\]and a prediction function:
\[\hat{\pi}_t, \hat{v}_t = f_\psi(z_t)\]That is a useful way to think about world models for control. Predicting the parts of the future that would change the decision matters more than predicting everything.
Further reading
- World Models - the original interactive article by Ha and Schmidhuber.
- Learning Latent Dynamics for Planning from Pixels - PlaNet.
- Dream to Control: Learning Behaviors by Latent Imagination - Dreamer.
- Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model - MuZero.
- Learning and Querying Fast Generative Models for Reinforcement Learning - an early example of learned dynamics for RL.